Scraping with Nokogiri
Web scraping is the practice of parsing a site’s HTML (or even DOM) and extracting meaningful data from it. Scraping can be a bit tricky and it can be a divisive topic among developers. Scraping has the potential to be really powerful tool for obtaining data that isn’t available in a more convenient structured form such as a JSON API. However, scraping can also be really tricky to implement and prone to sudden failure when, for example, a website is updated without notice. This sometimes makes scraping applications feel like a bit like a cludge. Typically, scraping is a last resort. We usually think of Web pages as something that are built to be viewed and processed one at a time by human beings rather than being analyzed en-mass by a machine. Thus, building a web scraper usually means putting a web site to a task that is neither intended nor supported by its maintainer.
A lot of my early experience with programming concepts came from trying to implement rudimentary scraping tools to ease some pain points in my typical work flow. Lately, I’ve been working on refreshing myself on how to add scraping into my Ruby toolbox using the popular Nokogiri gem. In this post, I’ll introduce what web scraping is and how to perform it using Ruby and Nokogiri.
What is Scraping and Why Use it?
As I mentioned, scraping is a technique for isolating data from a web page’s HTML. Scraping can be difficult to accomplish––in order to get the data one wants, one needs to closely analyze the HTML and identify exactly which page elements contain the sought-after information. It requires a great deal of precision which is further exacerbated by the challenge of scraping multiple similar pages on a website which may contain unforeseen differences.
Despite its challenges, scraping opens up a substantial world of potential data sources for developers to work with. For example, imagine one wanted some information on the grizzly deaths of some of your favorite characters in the expansive universe of Game of Thrones (not to be confused with A Song of Fire and Ice of course). Assuming that nobody has put up a structured data source for this information, one might still be able to programmatically obtain that data by writing a scraper to extract that data from the pages of the Game of Thrones Wikia.
Now that we’ve established the what let’s get into the how of web scraping.
Scraping HTML Using Nokogiri and Open-URI
Ruby has some powerful tools that we’ll want to make use when scraping.
Open-URI
Before we can begin the delicate work of parsing a web page, we need to obtain that web page from the internet. In Ruby, the Open-URI module is a great place to start. Open-URI provides the open method which takes a URL as an argument, and returns the HTML content of that URL.
For example, running
html = open('http://gameofthrones.wikia.com/wiki/Robb_Stark')
requests the GoT Wikia page for Robb Stark and makes it available through a variable called “html”. But what does one do with the HTML?
Nokogiri
Nokogiri is a popular Ruby gem for parsing HTML so that information can ultimately be extracted from it. Nokogiri empowers programmers to interact with an a huge string of HTML as a structured hierarchy. Nokogiri’s function of parsing HTML is similar to some of the functions of a web browser when rendering a web site. In addition to parsing HTML for us, Nokogiri also provides a number of methods that are useful for locating and extracting just the desired information from this parsed HTML.
Installing Nokogiri
While Open-URI is built in to Ruby, Nokogiri needs to be installed separately. Typically all this installation will require is executing gem install nokogiri. If you run into any issues with this, check out the Nokogiri Installation Guide.
Opening a Web Page as HTML with Nokogiri and Open-URI
Please note that the examples in this post are highly dependent upon the website they are scraping. In the future, if the website changes the examples in this post may no longer yield the results described.
Let’s say we have a file, main.rb which is responsible for running the scraping code. In main.rb we need to require Nokogiri and Open-URI:
require 'nokogiri'
require 'open-uri'
We can use the following line to grab the HTML that makes up the Nokogiri Project’s landing page at nokogiri.org:
html = open("http://www.nokogiri.org/")
Next, we’ll use the Nokogiri::HTML method to take the string of HTML returned by Open-URI’s open method and convert it into what Nokogiri terms a “NodeSet” and store it as a variable named “page”.
page = Nokogiri::HTML(html)
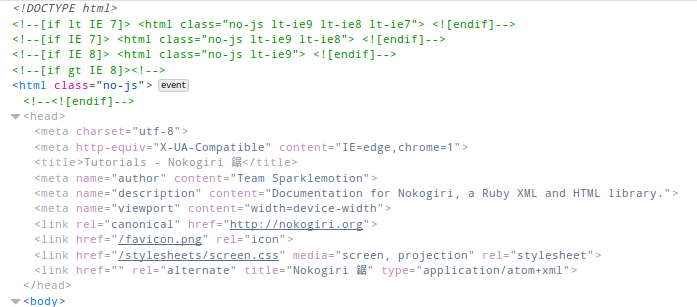
So what does this look like? The output of puts page is something like this:
<!DOCTYPE html>
<!--[if lt IE 7]> <html class="no-js lt-ie9 lt-ie8 lt-ie7"> <![endif]-->
<!--[if IE 7]> <html class="no-js lt-ie9 lt-ie8"> <![endif]-->
<!--[if IE 8]> <html class="no-js lt-ie9"> <![endif]-->
<!--[if gt IE 8]><!-->
<html class="no-js">
<!--<![endif]-->
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
<title>Tutorials - Nokogiri 鋸</title>
<meta name="author" content="Team Sparklemotion">
<meta name="description" content="Documentation for Nokogiri, a Ruby XML and HTML library.">
<meta name="viewport" content="width=device-width">
<link rel="canonical" href="http://nokogiri.org">
<link href="/favicon.png" rel="icon">
<link href="/stylesheets/screen.css" media="screen, projection" rel="stylesheet">
<link href="" rel="alternate" title="Nokogiri 鋸" type="application/atom+xml">
</head>
<body>
/* And so forth and so on */
The truncated text above is a parsed representation of the HTML that makes up the Nokogiri website’s landing page. If you don’t believe me, visit Nokogiri Project landing page and use your browser’s developer tools to inspect the page.
You should see something like this:
This element inspector view displays the browser’s own representation of the page’s HTML to us! In fact, the HTML it is showing us is exactly the same as the HTML put out to our terminal by main.rb with the help of Nokogiri and Open-URI.
This is good, but Nokogiri can do a lot more to make working with this page easier! This NodeSet’s nested structure allows it to be worked with using many of the same techniques that one might use to work with a nested object in Ruby such as iterators and [] notation.
Using CSS Selectors to Get Data
Nokogiri allows you to use CSS selectors in order to retrieve specific pieces of information from an HTML document.
What is a CSS Selector
Consider the following code:
<div id="the-div">
<p class="the-paragraph">
Hello Readers!
</p>
</div>
The “id” and “class” attributes of the HTML elements are examples of useful CSS selectors. One might ‘select’ or refer to the “div” element with the selector: #the-div. The # in this case indicates that it is referring to an id attribute. All together #the-div is a selector for HTML elements with an id attribute of “the-div”. Similarly, the paragraph element might be selected using the selector .my-paragraph. The . in this selector to denotes that the selected elements should have a class attribute equal to “my-paragraph”.
Nokogiri’s .css Method
Nokogiri’s css method can be called on the page variable that is assigned to the NodeSet that Nokogiri provides. The Nokogiri css method takes in an argument of a CSS selector and returns the selected element(s).
Choosing a CSS Selector
So let’s imagine that one the Nokogiri site one wants to extract the statement in the right hand corner that reads “Powered by Octopress. Theme is Oscailte.” How would one do that? A good place to start would be examining that area of the page in a browser inspector and seeing what CSS selectors might be available. This sentence is all in a single element with a class of “pull-right”. Not so fast! While using Nokogiri’s css method with a selector argument of .pull-right would return the desired element it would also return a good deal of the top navigation bar which is also of the “pull-right” class. This semantically makes sense because both elements have css styling that, indeed, pulls them to the right of the page. In order to obtain only the site engine/theme statement from the bottom right of the page, a more specific selector is needed. Re-running the command with an argument that limits the selector only to span elements (span.pull-right) should return only the desired portion of the page.
Calling the .css method
Themain.rb file of this demo project should have the following code:
require 'nokogiri'
require 'open-uri'
html = open('http://www.nokogiri.org')
page = Nokogiri::HTML(html)
The next step is to call the css method on page with the CSS selector from above by adding:
page.css(".span.pull-right")
Running puts on the result of that method call should display:
<span class="pull-right">
Powered by <a href="//octopress.org/">Octopress</a>. Theme is <a href="//github.com/coogie/oscailte">Oscailte</a>.
</span>
So close! To isolate just the text from this element, store the above output
as eng_theme_el and call the text method on it like so:
require 'nokogiri'
require 'open-uri'
html = open('http://www.nokogiri.org')
page = Nokogiri::HTML(html)
eng_theme_el = page.css("span.pull-right")
eng_theme_el.text
Running puts on the result of that method call should display:
Powered by Octopress. Theme is Oscailte.
There it is!
Iterating over elements
Sometimes it is helpful to get a collection of the same elements, so that one can iterate over them.
As an example, I’ll use the list of tutorials on the Nokogiri Project’s landing page.
To obtain these elements, I can use the following code in main.rb:
require 'nokogiri'
require 'open-uri'
html = open('http://www.nokogiri.org')
page = Nokogiri::HTML(html)
tutorials = page.css(".page > ol > li")
Here the > is denoting that only elements the are children of the prior selector should match. Thus, I’m looking for all “li” elements which are children of an “ol” element which is itself a child of an element with class “page”.
The return type of this method will be Nokogiri::XML::NodeSet which acts a bit like a Ruby array so it responds to Ruby methods, such as .each and .collect, to iterate over it. The tutorials NodeSet currently looks something like this:
[
#<Nokogiri::XML::Element:0x2aae8bcd7184
name="li"
children=[#<Nokogiri::XML::Element:0x2aae8bcd6810
name="a"
attributes=[#<Nokogiri::XML::Attr:0x2aae8bcd66d0
name="href"
value="/tutorials/installing_nokogiri.html">]
children=[#<Nokogiri::XML::Text:0x2aae8bccdbc0 "Installing Nokogiri">]
>]
>,
#<Nokogiri::XML::Element:0x2aae8bccd044
name="li"
children=[#<Nokogiri::XML::Element:0x2aae8bccca18
name="a"
attributes=[#<Nokogiri::XML::Attr:0x2aae8bccc874
name="href"
value="/tutorials/parsing_an_html_xml_document.html">]
children=[#<Nokogiri::XML::Text:0x2aae8bcc3e68 "Parsing an HTML/XML document">]
>]
>,
/* AND SO FORTH */
While this can look a bit intimidating at first, if we look closely we can start to pick out what’s going. We’ve got a series of “li” Nokogiri:XML:Element objects each of which has an “a” element child with an “href” attribute and a child of type Nokogiri:XML:Text.
In HTML terms this corresponds nicely to the actual HTML which looks like this:
<li><a href="/tutorials/installing_nokogiri.html">Installing Nokogiri</a></li>
<li><a href="/tutorials/parsing_an_html_xml_document.html">Parsing an HTML/XML document</a></li>
<li><a href="/tutorials/searching_a_xml_html_document.html">Searching a XML/HTML document</a></li>
<li><a href="/tutorials/modifying_an_html_xml_document.html">Modifying an HTML/XML document</a></li>
<li><a href="/tutorials/ensuring_well_formed_markup.html">Ensuring well-formed markup</a></li>
<li><a href="/tutorials/getting_help.html">Getting Help</a></li>
<li><a href="/tutorials/security.html">Security</a></li>
<li><a href="/tutorials/more_resources.html">More Resources</a></li>
Here is a quick example of a main.rb that manipulates this date usefully:
require 'nokogiri'
require 'open-uri'
html = open('http://www.nokogiri.org')
page = Nokogiri::HTML(html)
tutorials = page.css(".page > ol > li")
counter = 1
tutorials.each do |li|
path = li.children[0].attributes["href"].value
url = "http://nokogiri.com#{path}"
puts "#{counter}. #{li.children[0].children} (#{url})"
counter += 1
end
This program requests the nokogiri.org HTML, parses that HTML, selects the list of tutorial links, loops through each list item and for each item puts out a line with the tutorial’s number, name, and its absolute link. so the final outcome looks like this:
1. Installing Nokogiri (http://nokogiri.com/tutorials/installing_nokogiri.html)
2. Parsing an HTML/XML document (http://nokogiri.com/tutorials/parsing_an_html_xml_document.html)
3. Searching a XML/HTML document (http://nokogiri.com/tutorials/searching_a_xml_html_document.html)
4. Modifying an HTML/XML document (http://nokogiri.com/tutorials/modifying_an_html_xml_document.html)
5. Ensuring well-formed markup (http://nokogiri.com/tutorials/ensuring_well_formed_markup.html)
6. Getting Help (http://nokogiri.com/tutorials/getting_help.html)
7. Security (http://nokogiri.com/tutorials/security.html)
8. More Resources (http://nokogiri.com/tutorials/more_resources.html)
Conclusion
Scraping is a powerful and at times challenging tool. This is a substantial topic and there is lots to learn. I’ve found the The Bastard’s Book of Ruby - Parsing HTML with Nokogiri to be a helpful resource as I try to get more comfortable with scraping.