First FOSS Contribution Pt. I
Over the past weeks I’ve been on a mission to actively contribute to free and open source software (FOSS). As regular readers might recall, I’ve mentioned in some recent posts that I have been working in my free time to have some contributions merged into a FOSS project. I’m pleased to report that I’ve managed to have a handful of my merge requests accepted.
This post is an opportunity for me reflect on the process and for readers to get a sense of what contributing to a new project might look like. Due to the scope of what I learned, I’ll be splitting this post in to a few parts.
Why Contribute to a FOSS Project?
I’ve spent the bulk of my professional life working with and for free and open source software projects. While I like to believe that my work made a significant contribution to those projects, I wasn’t in a position to focus on making technical contributions until I began working in software development. While I’m certainly proud of some of my own pet projects, I was really craving some of the experiences that my personal projects just didn’t provide:
- Working on a large-scale, sophisticated project;
- Collaboration with experienced senior developers and other stake holders; and
- Guaranteed production deployment of my code to real users.
There are a lot of reasons to contribute to FOSS but these were particular driving forces for me.
Selecting a FOSS Project
When it came time to pick a project to work on the choice was clear: GitLab. GitLab is a really incredible project that offers a huge suite of options for DevOps: it handles source code management via git, code reviews, project management, documentation, and CI/CD.
GitLab has what’s known as an “open-core” business model; in addition to their subscription revenue from the paid tier of their hosted service at GitLab.com, they offer a Community Edition of their software free of charge and sell licenses for various tiers of their Enterprise Edition which feature a number of additional features not found in the Community Edition.
GitLab is something that I rely on regularly. I’ve been running my own self-hosted installation of GitLab’s Community Edition for nearly three years and am also a user of the free tier of its hosted service. My GitLab is used for all sorts of projects including this website. In addition, over the past year or so an increasing number of open source projects have been migrating their systems over to GitLab so it is becoming an even more prevalent technology resource.
GitLab has all of the characteristics I could possibly want in a FOSS project to contribute to: written using familiar technology (Ruby on Rails), personal connection to the product, a substantial deployment base, and most important of all, a robust program for accepting contributions
Getting Started
In order to start contributing to GitLab I needed to get a development environment/workflow set up. This required me to install and configure the GitLab Developer Kit (GDK). As an primary desktop Linux user for nearly a decade, getting the GDK dependencies installed and configured was pretty painless for me. It was mostly just a few apt-get install commands on my Debian system and a little bit of configuration for RVM and NVM.
Once I had my system prepared, I forked the GitLab Community Edition repository and proceeded with installing GDK. I wasn’t really sure what to expect from this stage. GitLab is a fairly complex system with a number of different components that could be a real nightmare to work with unaided. One of things I most respect about GitLab, however, is the amount of time and energy that is spent on offering a huge selection of polished and well-documented mechanisms for easy installation and configuration. To my great relief, GDK seems to be right in line with GitLab’s typical focus on ease of use.
GDK was a little confusing to me at first because I didn’t quite understand what it was doing but in hindsight it really was pretty simple. All I needed to do was run the following commands in my terminal and anxiously patiently wait.
$ gem install gitlab-development-kit
$ gdk init
#[MYFORK] below is just my namespace on GitLab.com
$ gdk install gitlab_repo=https://gitlab.com/[MY-FORK]/gitlab-ce.git
$ support/set-gitlab-upstream
To spin up my development instance of GitLab I just had one more command to run: gdk run app. After a few moments waiting for GitLab to get itself up and running I was able to login with default admin credentials at http://localhost:3000 and see my work in the GitLab source reflected in real time.
Finding a First Issue to Work On
The project has a significant amount of documentation on important subjects such as contribution workflow, merge request guidelines, contribution acceptance criteria, style guide and more. This documentation is really important stuff for being a good citizen of the community and I would really like to be able to say that I carefully digested all of it before getting started. Realistically though, that just didn’t make sense. I skimmed over a number of these documents and took in the details that I felt were important. Thanks to my years of dealing with issues surrounding FOSS contributions generally and hanging around the GitLab community specifically, I was fairly comfortable with some assumptions about the workflow and generally just picking things up by carefully paying attention to how more senior contributors worked.
I decided to start with a search of the GitLab Community Edition issue tracker with a search for open issues, not assigned to a contributor, tagged with the label ‘Accepting Merge Requests’ and sorted by weight. The idea was to find issues that nobody was already working on that had been deemed appropriate for community contribution and that critically had been assigned a weight of 1 or 2 to signify that they would be relatively approachable for a first time contributor such as myself.
I browsed through the issues that matched these criteria and settled on an issue that felt ideal. The issue I picked, #50209, was ironically related to GitLab’s issue-tracking features themselves. A user reported an issue with the breadcrumbs section of the New Issue page. According to the report and confirmed by my own testing, when a user tried to create a new issue for a project on GitLab they were presented with a screen that looked something like the following:
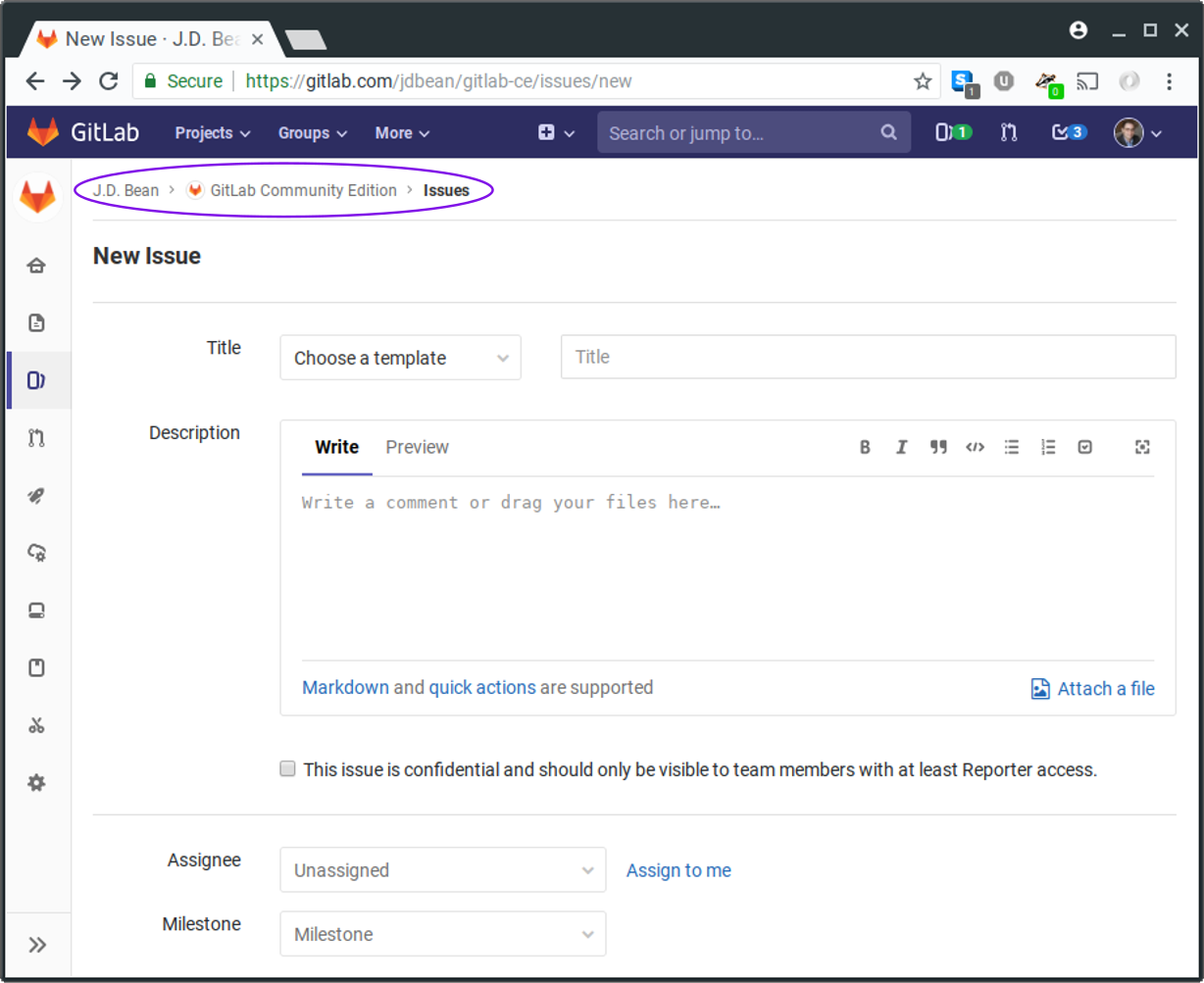 The GitLab “New Issue” page before my contribution
The GitLab “New Issue” page before my contribution
If one takes a look at the circled breadcrumbs section of the page one can see that the breadcrumbs go:
namespace > project > issues (bolded).
I imagine that most users would be confused that the New Issue page they were on was not included in the breadcrumbs and that when the Issues link was clicked the page they were on was simply reloaded rather than loading to the project’s Issues index page.
This seemed like the perfect issue for me to start in on. I reasoned that it was relatively self-contained, and would be easy for me to find the source of the problem in GitLab’s code and to quickly test the results of any changes I made. In line with GitLab’s procedure, I commented on the issue and confirmed that it was still accepting merge requests. A GitLab got myself assigned to the task.
Determining What the Resolution Should Be
The first question I needed to ask myself in resolving this issue was what exactly the desired behavior was. Was this something buried in the documentation under Rather than use my own judgment I decided to look for an analogous example in GitLab. The New Issue page was really just a form for creating a new Issue resource on a particular Project resource so I looked for similar patterns. I found a great example that showed a much more intuitive pattern:
namespace > project > [RESOURCE] > new (bolded).
I also found another instance of the same confusing pattern as the Issues resource on the New Merge Request page. I submitted a new issue for the New Merge Request breadcrumbs but decided not to start in on trying to fix it just yet. I reasoned that the fix for both issues would be pretty similar and that it would be better to wait until I had completed the first issue than to waste my time and the project’s by proposing potentially incorrect fixes for both problems and needing to redo both sets of changes.
Fixing the Issue
The patch that ultimately resolved the issue looks like this:
+ - add_to_breadcrumbs "Issues", project_issues_path(@project)
- - breadcrumb_title "Issues"
+ - breadcrumb_title "New"
- page_title "New Issue"
%h3.page-title
New Issue
%hr
= render "form"
I’d love to report that fixing this problem was as easy at it looks. Unfortunately, however, this seemingly minor change to a brief file represents hours of work.
A good portion of the time I spent working on this fix is attributable to simply getting familiar with this code. When I started out, I had the advantage of having already spent some time browsing through the GitLab source for my own edification. It had been a while since I had last worked on a large Rails project so it took me a while to get my bearings back. It took me a while to figure out some of the more advanced patterns being utilized by the code base such as Rails helpers.
It also been ages since the last time I had gone hunting for something specific in a sizable codebase that I wasn’t already deeply familiar with. After a little stumbling around I remembered two of my favorite debugging shortcuts. First, I remembered that I was working on a front-end problem which meant there might be some useful information hiding in the browser like class or id names that I could search through the codebase for. Second, I realized that there was already an example of code somewhere in the code base that achieved a similar outcome to what I wanted in an analogous situation. Thanks to these strategies and, a healthy dose of curiosity, I was not only able to implement the fix but also to understand how the the file I changed interacted with the rest of the codebase and how that changes I made ultimately produced the result that I wanted.
Celebration Time?
Not only had I learned a ton, but right there on my screen was my new version of GitLab with better breadcrumbs and I was ready to share it with the whole world.
I felt good! Really good. Like, Carleton-dance good.
Then I remembered that there was plenty more for me to do before having successful merge request ready. I needed to run the test suite to make sure that I hadn’t broken anything in the process of implementing my fix and I needed to add a changelog entry. Critically I needed to implement some tests to make sure that the issue stayed fixed.
I’ll cover all of that and more in Part II.